About data sources
Each data source defines the activity and fields from that activity to include in your dataset. Combine data sources in your dataset to reveal new insights and options for analysis.
There are several different ways you can work with data sources to add the data you need to your dataset.
- Add any combination of primary and secondary data sources, and optionally add up to 10 profile variables. Enhance the dataset with custom fields, scalar fields, weighting, and by appending external data from CSV files.
- Add one multiple response survey, and optionally add up to 10 profile variables. Enhance the dataset with custom fields, scalar fields, weighting, and by appending external data from CSV files.
- Add primary data sources only and apply data mapping. You can also optionally add up to 10 profile variables. You cannot use custom fields, scalar fields, weighting, or append external data from CSV files with data mapping.
Categories of Data Sources
There are two categories of data sources you can add to your dataset:
- Activity: These data sources specify an activity, and a set of fields from that activity, to include in your dataset. You select the activity to use, and the fields to include, based on the types of crosstab reports or dashboards you want to create. Each field is a survey question, and field values are the survey responses
- Profile
variable: These data sources allow you to add pieces of information
about community members to add more detail to your activity data sources. For
example, if your activity did not include a question asking for members'
birthdays, you could retrieve this value from a profile variable captured
separately from another app or loyalty program, and combine it with an activity
data source. Profile variables are captured in surveys, populated by
third-party integrations, or uploaded manually.
Note: Datasets only included profile variable values for Active Community members. If non-active members are included in the dataset with profile variable values, their profile variable value is the "Did not answer" answer option when crosstab reports are created using the dataset.
Combining data sources
Whenever you add multiple data sources to a dataset, you need to consider how the data sources are related. For example, you might want to choose activities where the same set of questions were asked of different members one year apart, or you might want to combine activities where a set of the same members completed a series of distinct activities.
You can add two source types of data sources to a dataset:
- Primary: The
first data source you add is a primary data source by default. Use primary data
sources to include each unique record in the activity source data in the
dataset. Each unique record represents a survey response. Use multiple primary
data sources to ensure that all of the unique records in each activity are
included. Multiple response surveys must be added as primary data sources.
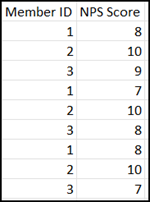
Example: Two primary data sources If the first data source has 5 unique members and the second data source has 5 unique members, with no overlap between the data sources, the combined dataset will have 10 members with all of the fields and values from both data sources populated. The dataset will have a row for each member. All of the selected fields from the first data source will be added as columns, and the fields from the second data source will be appended horizontally after the first data source columns.
Note: You must deselect the Apply Auto Mapping checkbox when you add the second primary data source to maintain the horizontal append behavior.
-
Secondary: Secondary data sources only include records if there is a matching member in the primary data source. If multiple primary data sources are defined, the row from the secondary data source will be included if there is a matching member in any of the primary data sources.
The dataset will include a row for each member in a primary data source. All of the selected fields from each activity will be appended as columns in the data set. Values for fields from secondary data sources will only be populated if they are associated with a member found in a primary data source.
Example: Primary and secondary data sources If the primary data source has 5 members, but only 2 matching members are found in the secondary data source, the resulting dataset will include the field values from all 5 members in the primary data source, but only the field values from the 2 overlapping members in the secondary data source. The 3 non-overlapping members in the secondary data source will be omitted.

Profile variables should typically be added as secondary data sources for single response surveys and power surveys, and must be added as secondary data sources for multiple response surveys. You only want to include the profile variable value for each member that exists in the primary data source(s). If you add the profile variable as a primary data source, your dataset will include the profile variable for every member in your community, which may have a significant performance impact for larger communities.
Mapping fields from primary data sources
When you add two or more single response surveys to a dataset as primary data sources, and no data mapping is defined, the default behavior when the dataset is synced is to have a row for each member ID and a column for each question in the first survey followed by a column for each question in the second survey. The data is arranged horizontally.

If you add single response surveys where some or all of the questions and response options are shared by multiple surveys, you can choose to map fields. When fields are mapped data from subsequent surveys is mapped to the field of the same name and type from the first survey instead of creating a new field. The data for mapped fields is arranged vertically. Fields that are not mapped or do not match are appended to the dataset horizontally as new columns.